linux内核基础
Linux内核结构¶
Linux作为一种开源计算机操作系统,其内核(Linux Kernel,后续称其为Kernel)由C语言编写。作为一种操作系统内核,其具备了操作系统内核应该具备的所有功能。如下图所示,Kernel起到了承上启下的作用,一方面能够控制并与硬件进行交互,另一方面向应用层提供了运行环境。通过内核可以实现I/O,权限控制,系统调用,进程管理,内存管理等多项功能。一旦Kernel出现了漏洞,那么就会对操作系统本身产生破坏,通常会引起重启。内核漏洞最常用于权限提升。

内核和用户空间的应用程序使用的是不同的保护地址空间。每个用户空间的进程都使用自己的虚拟地址空间,而内核则占用单独的地址空间。Intel CPU把CPU的特权级分为Ring 0,Ring 1,Ring 2,Ring3四种,其中Ring 0是内核使用的特权级,Ring 3 是所有程序都可以使用的特权级。内层特权级可以使用外层特权级的资源。使用这种的特权级的目的是为了操作系统的安全而进行权限隔离。
Linux内核可以进一步划分为3成,最上层是系统调用接口(SCI,System Call Interface),实现了基本的功能,例如open、read、write等;SCI层以下的内核代码,依赖于体系结构,被称为BSP(Board Support Package)的部分。这些代码用作给定体系结构的处理器和特定于平台的代码。
Linux 内核实现了很多重要的体系结构属性。在或高或低的层次上,内核被划分为多个子系统。Linux 也可以看作是一个整体,因为它会将所有这些基本服务都集成到内核中。这与微内核的体系结构不同,后者会提供一些基本的服务,例如通信、I/O、内存和进程管理,更具体的服务都是插入到微内核层中的。每种内核都有自己的优点。Linux编译后可在大量处理器和具有不同体系结构约束和需求的平台上运行。一个例子是Linux可以在一个具有内存管理单元(MMU)的处理器上运行,也可以在那些不提供MMU的处理器上运行。Linux内核的uClinux移植提供了对非MMU 的支持。
下面介绍Linux内核包含了哪些内容:
- 系统调用接口:SCI 层提供了某些机制执行从用户空间到内核的函数调用。正如前面讨论的一样,这个接口依赖于体系结构,甚至在相同的处理器家族内也是如此。SCI 实际上是一个非常有用的函数调用多路复用和多路分解服务;
- 进程管理:进程管理的重点是进程的执行。在内核中,这些进程称为线程,代表了单独的处理器虚拟化(线程代码、数据、堆栈和CPU寄存器)。在用户空间,通常使用进程 这个术语,不过Linux实现并没有区分这两个概念(进程和线程)。内核通过SCI提供了一个应用程序编程接口(API)来创建一个新进程,停止进程(kill、exit),并在它们之间进行通信和同步(signal或者POSIX机制)。进程管理还包括处理活动进程之间共享CPU的需求。内核实现了一种新型的调度算法,不管有多少个线程在竞争CPU,这种算法都可以在固定时间内进行操作。调度程序也可以支持多处理器(称为对称多处理器或SMP);
- 内存管理:如果由硬件管理虚拟内存,内存是按照所谓的内存页 方式进行管理的(对于大部分体系结构来说都是4KB)。Linux包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。不过内存管理要管理的可不止4KB缓冲区。Linux提供了对4KB缓冲区的抽象,例如slab分配器。这种内存管理模式使用4KB缓冲区为基数,然后从中分配结构,并跟踪内存页使用情况,比如哪些内存页是满的,哪些页面没有完全使用,哪些页面为空。这样就允许该模式根据系统需要来动态调整内存使用。为了支持多个用户使用内存,有时会出现可用内存被消耗光的情况。由于这个原因,页面可以移出内存并放入磁盘中。这个过程称为交换,因为页面会被从内存交换到硬盘上。Linux系统中,被用于交换的分区叫swap分区,在windows系统下叫做虚拟内存;
- 文件系统:虚拟文件系统(VFS)是Linux内核中非常有用的一个方面,因为它为文件系统提供了一个通用的接口抽象。VFS在SCI和内核所支持的文件系统之间提供了一个交换层。在VFS上面,是对诸如open、close、read和write之类的函数的一个通用API抽象。在VFS下面是文件系统抽象,它定义了上层函数的实现方式;
- 网络管理:网络堆栈在设计上遵循模拟协议本身的分层体系结构;
- 设备驱动:Linux内核中有大量代码都在设备驱动程序中,它们能够运转特定的硬件设备。Linux源码树提供了一个驱动程序子目录,这个目录又进一步划分为各种支持设备,例如 Bluetooth、I2C、serial等。
可加载核心模块¶
可加载核心模块(Loadable Kernel Modules,简称LKMs)是运行在内核空间的可执行程序,包括驱动程序(设备驱动、文件系统驱动等)、内核扩展模块。在Linux中,LKMs的文件格式和Ring3的可执行程序格式一样,均为ELF文件格式。模块可以被单独编译,但不能单独运行。它在运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户控件的进程不同。模块通常用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
使用LKMs的原因是因为Linux内核本事是一个单内核,效率高,因为所有的内容都集合在一起,但是缺少可扩展行和可维护性,因此需要使用LKMs。大部分的内核题目基本都是会处在LKM中。
下表中给出了linux中常见的LKMs的操作指令:
| 指令 | 描述 |
|---|---|
| insmod | 加载模块到内核中 |
| rmmod | 在内核中卸载模块 |
| lsmod | 枚举系统中已经加载的模块 |
系统调用¶
系统调用(syscall)指用户态运行的程序向内核请求高权限的服务,其本质是用户态和内核态的接口。很多库函数,比如scanf、puts等IO相关函数都是对系统调用的封装。
man手册中的ioctl:
Name
ioctl - control device
Synopsis
#include <sys/ioctl.h>
int ioctl(int d, int request, ...);
Description
The ioctl() function manipulates the underlying device parameters of special files. In particular, many operating characteristics of character special files (e.g., terminals) may be controlled with ioctl() requests. The argument d must be an open file descriptor.
The second argument is a device-dependent request code. The third argument is an untyped pointer to memory. It's traditionally char *argp (from the days before void * was valid C), and will be so named for this discussion.
An ioctl() request has encoded in it whether the argument is an in parameter or out parameter, and the size of the argument argp in bytes. Macros and defines used in specifying an ioctl() request are located in the file <sys/ioctl.h>.
Return Value
Usually, on success zero is returned. A few ioctl() requests use the return value as an output parameter and return a nonnegative value on success. On error, -1 is returned, and errno is set appropriately.
ioctl是一个用于和设备通信的系统调用。int ioctl(int fd, unsigned long request, ...)中第一个参数为打开设备返回的文件描述符,第二个参数为用户程序对设备的控制指令,后面的参数是补充参数,和设备本身相关。
Linux操作系统提供了内核访问标准外部设备的系统调用,比如IO。当访问非标准的硬件设备时因为过分复杂的情况,是很难去提供充足的系统调用的。因此内核被设计为可扩展的,可以加入设备驱动模块,驱动代码允许在内核空间运行并且可以对设备直接寻址。一个ioctl接口就是一个独立的系统调用,用户态可以通过这个接口直接跟设备沟通,对设备驱动的请求是一个以设备和请求号码为参数的ioctl调用。
接下来我们详细介绍一下系统调用的流程。Int $0x80指令的目的是产生一个编号为128的编程异常,这个编程异常对应的是中断描述符表IDT中的第128项——也就是对应的系统门描述符。门描述符中含有一个预设的内核空间地址,它指向了系统调用处理程序:system_call()。Linux为每个系统调用都进行了编号(0—NR_syscall),同时在内核中保存了一张系统调用表,该表中保存了系统调用编号和其对应的服务例程,因此在系统调入通过系统门陷入内核前,需要把系统调用号一并传入内核,在x86上,这个传递动作是通过在执行int0x80前把调用号装入eax寄存器实现的。这样系统调用处理程序一旦运行,就可以从eax中得到数据,然后再去系统调用表中寻找相应服务例程了。除了需要传递系统调用号以外,许多系统调用还需要传递一些参数到内核,比如sys_write(unsigned int fd, const char * buf, size_t count)调用就需要传递文件描述符fd、要写入的内容buf、以及写入字节数count等几个内容到内核。碰到这种情况,Linux会有6个寄存器可被用来传递这些参数:eax(存放系统调用号)、ebx、ecx、edx、esi及edi来存放这些额外的参数。当服务例程结束时,system_call()从eax获得系统调用的返回值,并把这个返回值存放在曾保存用户态 eax寄存器栈单元的那个位置上。然后跳转到ret_from_sys_call(),终止系统调用处理程序的执行。当进程恢复它在用户态的执行前,RESTORE_ALL宏会恢复用户进入内核前被保留到堆栈中的寄存器值。其中eax返回时会带回系统调用的返回码。(负数说明调用错误,0或正数说明正常完成)
内核切换机制¶
CPU从用户态切换到内核态的条件是发生系统调用、异常、外设中断等事件,具体过程可以参考如下代码:
ENTRY(entry_SYSCALL_64) SWAPGS_UNSAFE_STACK GLOBAL(entry_SYSCALL_64_after_swapgs) movq %rsp, PER_CPU_VAR(rsp_scratch) movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp TRACE_IRQS_OFF /* Construct struct pt_regs on stack */ pushq $__USER_DS /* pt_regs->ss */ pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */ pushq %r11 /* pt_regs->flags */ pushq $__USER_CS /* pt_regs->cs */ pushq %rcx /* pt_regs->ip */ pushq %rax /* pt_regs->orig_ax */ pushq %rdi /* pt_regs->di */ pushq %rsi /* pt_regs->si */ pushq %rdx /* pt_regs->dx */ pushq %rcx /* pt_regs->cx */ pushq $-ENOSYS /* pt_regs->ax */ pushq %r8 /* pt_regs->r8 */ pushq %r9 /* pt_regs->r9 */ pushq %r10 /* pt_regs->r10 */ pushq %r11 /* pt_regs->r11 */ sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
通过代码可以分析出用户态切换到内核态时做了哪些事情(entry_SYSCALL_64):
- 执行了swapgs指令,交换GS寄存器值和特定位置的内核执行时的GS值;
- 将用户空间栈顶记录在CPU独占变量区域中,将CPU独占区域中记录的内核栈顶放入rsp/esp;
- 通过push保存各个寄存器的值,形成了一个pt_regs结构;
- 判断是否为x32_abi;
- 根据系统调用号跳到全局变量sys_call_table相应位置继续执行系统调用。CPU从内核态回复到用户态时会执行:
- 通过swapgs恢复GS值;
- 通过sysretq或者iretq恢复用户态的寄存器信息。
cred结构体¶
Kernel记录了进程的权限等相关信息,使用就是cred结构体。每个进程都会有一个cred结构与其对应,结构中存储了该进程权限等信息,例如uid、gid,如果能够修改某个进程的cred,也就实现了这个进程的权限的修改。Cred结构体如下所示:
struct cred { atomic_t usage; #ifdef CONFIG_DEBUG_CREDENTIALS atomic_t subscribers; /* number of processes subscribed */ void *put_addr; unsigned magic; #define CRED_MAGIC 0x43736564 #define CRED_MAGIC_DEAD 0x44656144 #endif kuid_t uid; /* real UID of the task */ kgid_t gid; /* real GID of the task */ kuid_t suid; /* saved UID of the task */ kgid_t sgid; /* saved GID of the task */ kuid_t euid; /* effective UID of the task */ kgid_t egid; /* effective GID of the task */ kuid_t fsuid; /* UID for VFS ops */ kgid_t fsgid; /* GID for VFS ops */ unsigned securebits; /* SUID-less security management */ kernel_cap_t cap_inheritable; /* caps our children can inherit */ kernel_cap_t cap_permitted; /* caps we're permitted */ kernel_cap_t cap_effective; /* caps we can actually use */ kernel_cap_t cap_bset; /* capability bounding set */ kernel_cap_t cap_ambient; /* Ambient capability set */ #ifdef CONFIG_KEYS unsigned char jit_keyring; /* default keyring to attach requested * keys to */ struct key __rcu *session_keyring; /* keyring inherited over fork */ struct key *process_keyring; /* keyring private to this process */ struct key *thread_keyring; /* keyring private to this thread */ struct key *request_key_auth; /* assumed request_key authority */ #endif #ifdef CONFIG_SECURITY void *security; /* subjective LSM security */ #endif struct user_struct *user; /* real user ID subscription */ struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */ struct group_info *group_info; /* supplementary groups for euid/fsgid */ struct rcu_head rcu; /* RCU deletion hook */ } __randomize_layout;
内核态函数和符号¶
介绍下Linux内核中的重要函数。
- printk():内核态的打印函数,但是输出不是终端,而是内核缓冲区,可以通过dmesg查看。
- copy_from_user()/copy_to_user():内核态和用户态数据传输的函数,前者实现了用户态数据向内核态的传输,后者实现了内核态数据向用户态传输。
- kmalloc():内核态的内存分配函数,使用的是slab/slub分配器。
- commit_creds(struct cred *new):将新的cred结构应用于当前进程;
- struct cred* prepare_kernel_cred(struct task_struct* daemon):创建一个新的cred结构。
通常来说如果可以在内核中执行commit_creds(prepare_kernel_cred(0)),就可以设置当前进程的uid和gid为0,实现本地提权。
如下图,可以通过查看/proc/kallsyms来获取两个函数的地址。
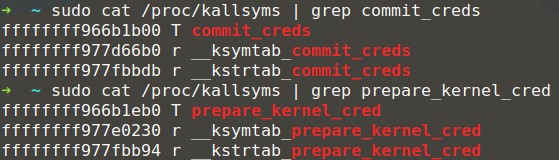
下面介绍一下内核符号表。Linux内核是个整体结构,模块是掺入其中的插件。当然我们也可以把内核整体看做一个大模块。那么模块和模块之间交互一种常用的方法就是共享变量和函数,但是并不是模块中的每个变量和函数都能被共享,内核中只把各个模块中主要的变量和函数放在一个特定的区段,这些变量和函数就称为符号。在kernel/ksyms.c中定义了可以从内核这个特殊的“模块”中可以export的符号,例如进程管理子系统,那么可以export的符号如下:
/*进程管理 */ EXPORT_SYMBOL(do_mmap_pgoff); EXPORT_SYMBOL(do_munmap); EXPORT_SYMBOL(do_brk); EXPORT_SYMBOL(exit_mm); … EXPORT_SYMBOL(schedule); EXPORT_SYMBOL(jiffies); EXPORT_SYMBOL(xtime); …
这些符号原本是内核内部的符号,通过EXPORT_SYMBOL这个宏后就会被放在一个公开的地方,使得装入到内核中的其他模块可以应用它们。仅仅知道符号的名字是不够的,还需要知道它们在内核空间中的地址才有意义。内核中定义了如下结构来描述模块的符号:
struct module_symbol
{
unsigned long value;/*符号在内核地址空间中的地址*/
const char *name; /*符号名*/
};
/proc/ksyms(2.6以后版本通过/proc/kallsyms)文件可以读出所有内核模块export的符号(如图x.2),这些符号就形成了内核符号表,其格式为:
- 内存地址 符号名 [所属模块]
在Linux模块变成中,可以根据符号名直接从这个文件中检索出其对应的地址,然后直接访问该地址就可以获得内核数据。如果符号是从内核(那个母模块)直接export的,那么第三列的所属模块就会为空。
内核符号表记录了所有模块可以访问的符号及相应的地址,当一个新的模块被装入内核后,其声明的某些符号就会被登记到这个表中,并且就可能被其他模块所引用,这个就是模块依赖。模块A引用模块B的export出来符号,那么就是模块B被模块A引用,或者说模块A依赖于模块B。如果要链接模块A,必须先链接模块B。
因为有模块依赖,所以为了确保模块安全地卸载,每个模块都使用了一个引用计数器。当执行模块所涉及的操作时就递增计数器,在操作结束时就递减这个计数器;另外,当模块B被模块A引用 时,模块B的引用计数就递增,引用结束,计数器递减。什么时候可以卸载这个模块?当然只有这个计数器值为0的时候。
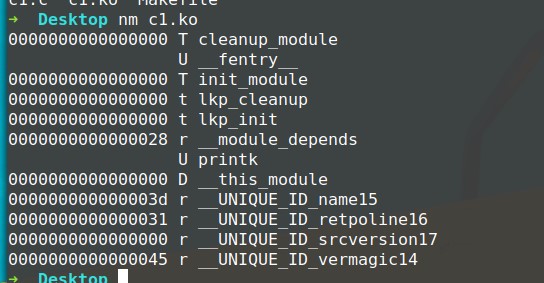
另外如下图所示,我们可以使用nm指令来列出ko文件中的符号:
内核内存分配¶
内核中也需要使用到内存的分配,类似于用户空间malloc的功能。在内核中没有libc,所以没有malloc,但是需要这样的功能,所以有kmalloc,其实现是使用的slab/slub分配器,现在多见的是slub分配器。这个分配器通过一个多级的结构进行管理。首先有cache层,cache是一个结构,里边通过保存空对象,部分使用的对象和完全使用了对象来管理,对象就是指内存对象,也就是用来分配或者已经分配的一部分内核空间。kmalloc使用了多个cache,一个cache对应一个2的幂大小的一组内存对象。slab分配器严格按照cache去区分,不同cache的无法分配在一页内,slub分配器则较为宽松,不同cache如果分配相同大小,可能会在一页内。
漏洞缓冲机制¶
- Dmesg Restrictions:通过设置/proc/sys/kernel/dmesg_restrict为1,可以将dmesg输出的信息视为敏感信息(默认为0);
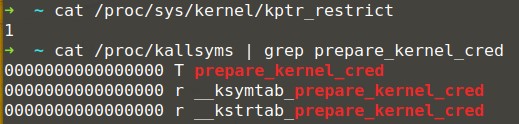
- Kernel Address Display Restriction:/proc/sys/kernel/kptr_restrict被默认设置为1,导致无法通过/proc/kallsyms获取内核地址,如下图;
- Kernel PageTable Isolation:KPTI,内核页表隔离,进程地址空间被分成了内核地址空间和用户地址空间,其中内核地址空间映射到了整个物理地址空间,而用户地址空间只能映射到指定的物理地址空间。内核地址空间和用户地址空间共用一个页全局目录表。为了彻底防止用户程序获取内核数据,可以令内核地址空间和用户地址空间使用两组页表集。Windows称其为KVA Shadow;
- Kernel ASLR:内核地址空间布局随机化;
- SMAP/SMEP:SMAP(Supervisor Mode Access Prevention,管理模式访问保护)和SMEP(Supervisor Mode Execution Prevention,管理模式执行保护)的作用分别是禁止内核访问用户空间的数据和禁止内核执行用户空间的代码。arm里面叫PXN(Privilege Execute Never)和PAN(Privileged Access Never)。和NX一样SMAP/SMEP需要处理器支持,如下图,可以通过cat /proc/cpuinfo查看,在内核命令行中添加nosmap和nosmep禁用,是否开启由CPU的CR4寄存器管理.
 在没有SMAP/SMEP的情况下把内核指针重定向到用户空间的漏洞利用方式被称为ret2usr。physmap是内核管理的一块非常大的连续的虚拟内存空间,为了提高效率,该空间地址和RAM地址直接映射。RAM相对physmap要小得多,导致了任何一个RAM地址都可以在physmap中找到其对应的虚拟内存地址。另一方面,我们知道用户空间的虚拟内存也会映射到RAM。这就存在两个虚拟内存地址(一个在physmap地址,一个在用户空间地址)映射到同一个RAM地址的情况。也就是说,我们在用户空间里创建的数据,代码很有可能映射到physmap空间。基于这个理论在用户空间用mmap()把提权代码映射到内存,然后再在physmap里找到其对应的副本,修改EIP跳到副本执行就可以了。因为physmap本身就是在内核空间里,所以SMAP/SMEP都不会发挥作用。这种漏洞利用方式叫ret2dir。关闭SMEP方法修改 /etc/default/grub 文件中的GRUB_CMDLINE_LINUX="",加上nosmep/nosmap/nokaslr,然后 update-grub 就好;
在没有SMAP/SMEP的情况下把内核指针重定向到用户空间的漏洞利用方式被称为ret2usr。physmap是内核管理的一块非常大的连续的虚拟内存空间,为了提高效率,该空间地址和RAM地址直接映射。RAM相对physmap要小得多,导致了任何一个RAM地址都可以在physmap中找到其对应的虚拟内存地址。另一方面,我们知道用户空间的虚拟内存也会映射到RAM。这就存在两个虚拟内存地址(一个在physmap地址,一个在用户空间地址)映射到同一个RAM地址的情况。也就是说,我们在用户空间里创建的数据,代码很有可能映射到physmap空间。基于这个理论在用户空间用mmap()把提权代码映射到内存,然后再在physmap里找到其对应的副本,修改EIP跳到副本执行就可以了。因为physmap本身就是在内核空间里,所以SMAP/SMEP都不会发挥作用。这种漏洞利用方式叫ret2dir。关闭SMEP方法修改 /etc/default/grub 文件中的GRUB_CMDLINE_LINUX="",加上nosmep/nosmap/nokaslr,然后 update-grub 就好; - Stack Protector:和用户态相同,canary;
- Address Protection:内核空间和用户空间共享虚拟内存地址,因此需要防止用户空间mmap的内存从0开始,从而缓解空指针引用攻击。windows系统从win8开始禁止在零页分配内存。从linux内核2.6.22开始可以使用sysctl设置mmap_min_addr来实现这一保护。
CTF中的Linux Kernel题目¶
CTF中的Linux Kernel题目会使用qemu启动,通常来说会给以下三个文件: 1. boot.sh:启动kernel的shell脚本,可以根据不同的启动参数的值看出不同的保护措施; 2. bzImage:内核的binary; 3. rootfs.cpio:启动的文件系统,通常会在里面放置一个假的flag,可以通过cpio进行解压(cpio -idmv < rootfs.cpio)。
也有可能会给内核的源码和ko文件,如果没有给ko文件,那可以通过解cpio文件得到ko文件。
然后需要了解的就是qemu的启动参数:
#!/bin/sh cd /home/gnote stty intr ^] exec timeout 120 qemu-system-x86_64 -m 64M -kernel bzImage -initrd rootfs.cpio -append "loglevel=3 console=ttyS0 oops=panic panic=1 kaslr" -nographic -net user -net nic -device e1000 -smp cores=2,threads=2 -cpu kvm64,+smep -monitor /dev/null 2>/dev/null
其他参数都较容易理解,这里有几个参数需要格外注意:
- -append "loglevel=3 console=ttyS0 oops=panic panic=1 kaslr":这个参数开启了kaslr;
- -smp cores=2,threads=2:这个参数制定了核数;
- -cpu kvm64,+smep:这个参数开启了kvm,并且开启了smep;
- -m 64M:这个参数设置了虚拟RAM的大小,默认为128M;
- -monitor /dev/null 2>/dev/null:这个参数关闭了qemu的monitor模式,如果没有关闭的话,我们是可以直接通过qemu的monitor模式得到flag的,这个经常会有CTF出题者因为没有注意而导致非预期解。
还有一个较为有用的文件是cpio中的init文件:
#!/bin/sh /bin/mount -t devtmpfs devtmpfs /dev chown root:tty /dev/console chown root:tty /dev/ptmx chown root:tty /dev/tty mkdir -p /dev/pts mount -vt devpts -o gid=4,mode=620 none /dev/pts mount -t proc proc /proc mount -t sysfs sysfs /sys echo 2 > /proc/sys/kernel/kptr_restrict echo 1 > /proc/sys/kernel/dmesg_restrict #echo 0 > /proc/sys/kernel/kptr_restrict #echo 0 > /proc/sys/kernel/dmesg_restrict ifup eth0 > /dev/null 2>/dev/null insmod gnote.ko ……
init文件中有系统启动的时候的信息,可以看到开了哪些内核保护措施以及题目做的一些奇怪的操作。
编写和分析一个Kernel程序¶
本节我们尝试编写一个Kernel程序并在Linux操作系统中运行,然后分析一下源码并进行逆向。首先编写一个简单的Kernel程序:
#include <linux/module.h> #include <linux/kernel.h> #include <linux/init.h> static int __init lkp_init( void ) { printk("Hello,World!\n"); return 0; } static void __exit lkp_cleanup( void ) { printk("Goodbye, World!\n"); } module_init(lkp_init); module_exit(lkp_cleanup);
首先对程序源码进行分析,首先是头文件,linux/module.h是Linux内核模块变成必须包含的头文件,头文件kernel.h包含了常用的内核函数,头文件init.h包含了宏_init和_exit,它们允许释放内核占用的内存。接下来是lkp_init函数,这个是模块的初始化函数,它会在内核模块被加载的时候执行,使用__init进行修饰,一般用它来初始化数据结构等内容;lkp_cleanup函数是模块的退出函数,他会在模块在退出的时候执行。函数module_init()和cleanup_exit()是模块编程中最基本也是必须的两个函数,它用来指定模块加载和退出时调用的函数,这里加载的是我们上面定义好的两个函数。上述两个函数必须在内核模块中包含,module_init()向内核注册模块所提供的新功能,而cleanup_exit()注销由模块提供的所有功能。这段代码中使用了printk函数,这是内核的打印函数,可以使用dmesg指令看到内核打印的信息。
接下来我们编译这段代码,首先我们要制作一个Makefile文件:
KERNAL_DIR ?= /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) obj-m := c1.o modules: $(MAKE) -C $(KERNAL_DIR) M=$(PWD) modules @make clear clear: @rm -f *.o *.cmd *.mod.c @rm -rf *~ core .depend .tmp_versions Module.symvers modules.order -f @rm -f .*ko.cmd .*.o.cmd .*.o.d @rm -f *.unsigned clean: @rm -f c1.ko
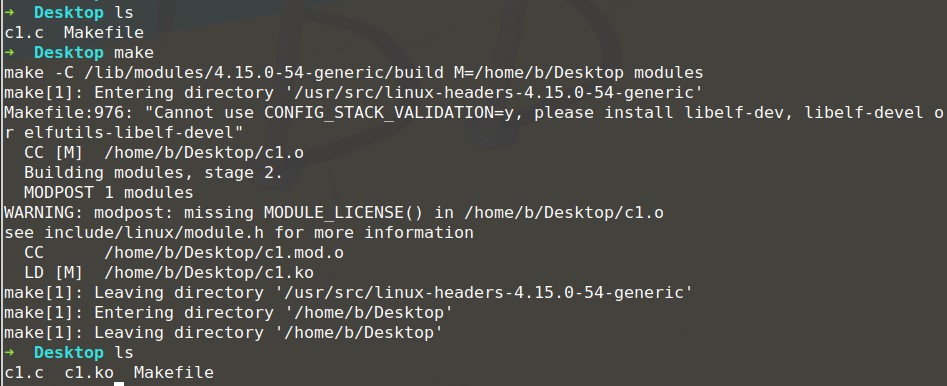
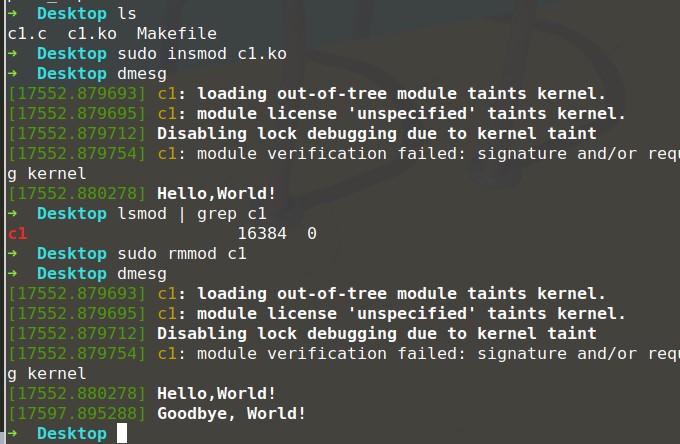
把内核模块的代码放置在c1.c中,然后make,如上图所示,执行完成后,就可以得到ko文件。接下来可以dmesg查看Linux内核的打印信息,dmesg -c将会清除之前Linux内核的打印信息。如图下所示,我们可以使用insmod安装模块,然后使用dmesg查看内核打印的信息;然后使用lsmod可以看到内核安装的模块;最后使用rmmod卸载模块,然后再次使用dmesg查看内核打印的信息。
对编译好的ko文件进行逆向,如下图所示,只有简单的4个函数,init函数中首先执行了一个function entry(用来做function tracing的,插桩),然后就是printk;exit函数中只执行了printk。


上述的代码: 传送门
Reference¶
https://github.com/ctf-wiki/ctf-wiki/blob/master/docs/pwn/linux/kernel/ref/13_lecture.pdf
https://ctf-wiki.github.io/ctf-wiki/
https://www.kernel.org/doc/html/latest/core-api/kernel-api.html
https://zh.wikipedia.org/wiki/内核
http://www.freebuf.com/articles/system/54263.html
https://blog.csdn.net/qq_16124631/article/details/28921361
https://blog.csdn.net/zqixiao_09/article/details/50839042
https://yq.aliyun.com/articles/53679